外部数据包装器(FDW)
使用 Postgres 外部数据封装器连接外部系统
外部数据封装器(FDW)是 Postgres 的一个核心特性,它允许您访问和查询存储在外部数据源中的数据,就像它们是本地 Postgres 表一样。
Postgres 包括几个内置的外部数据封装器,例如 postgres_fdw 用于访问其他 PostgreSQL 数据库,以及file_fdw 用于从文件中读取数据。Supabase 扩展了这一特性,以便查询其他数据库或任何其他外部系统。我们通过开源 Wrappers 框架来实现这一点。在这些指南中,我们将它们称为“Wrappers”,外部数据封装器或 FDWs。它们在概念上是相同的。
概念
Wrappers 引入了一些新的术语和不同的工作流程。
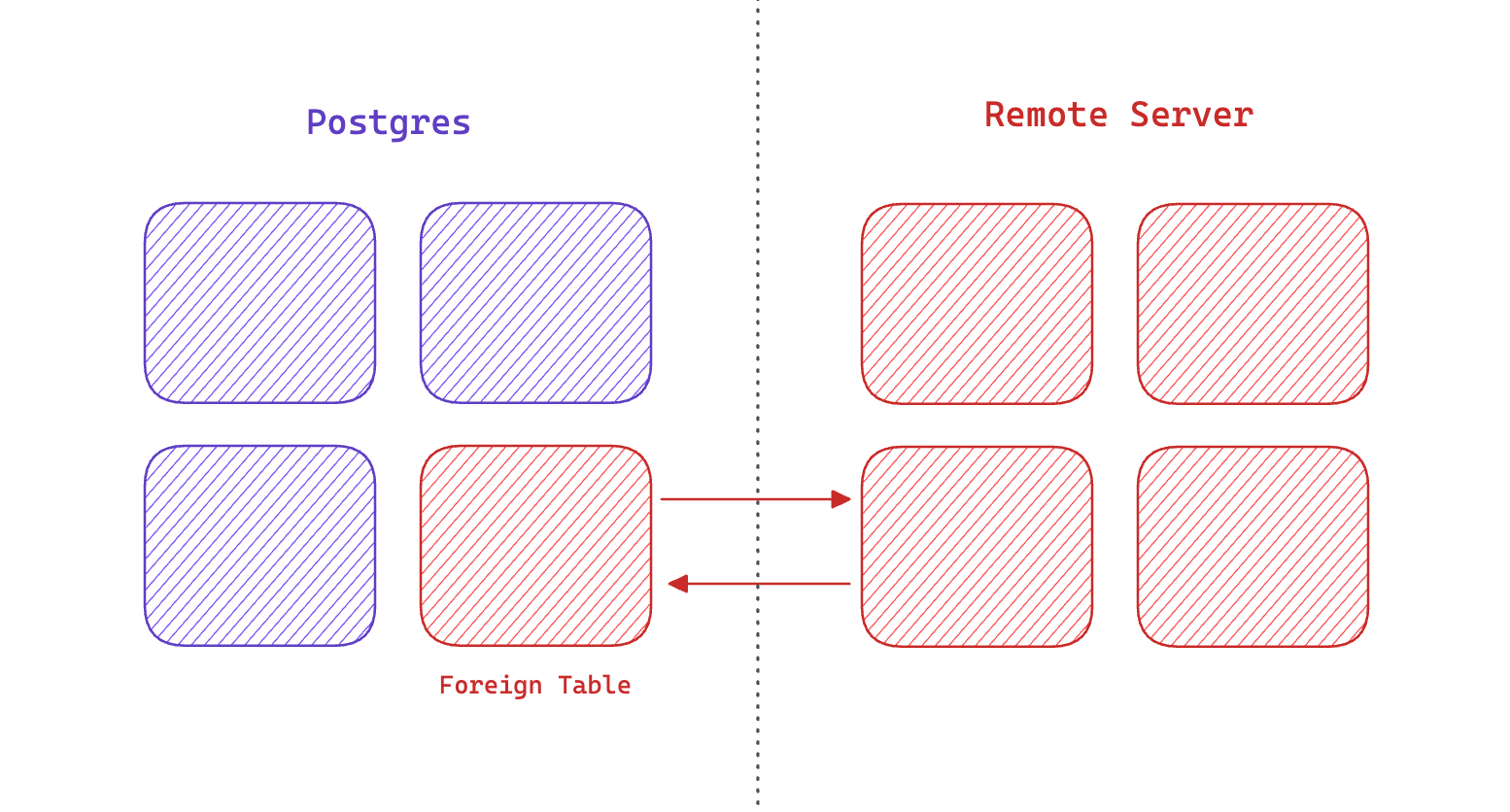
远程服务器
远程服务器是您想要从 Postgres 数据库查询数据的外部数据库、API 或任何包含数据的系统。示例包括:
- 一个外部数据库,如 Postgres 或 Firebase。
- 一个远程数据仓库,如 ClickHouse、BigQuery 或 Snowflake。
- 一个 API,如 Stripe 或 GitHub。
您可以连接多个同类型的远程服务器。例如,您可以在同一个 Supabase 数据库中连接到两个不同的 Firebase 项目。
外部表
外部表,即映射到远程服务器内部某些数据的数据库中的表。
示例:
一个 analytics 表,映射到您的数据仓库内部的表。
一个 subscriptions 表,映射到您的 Stripe 订阅。
一个 collections 表,映射到 Firebase 集合。
尽管外部表的行为像任何其他表一样,但数据并不存储在您的数据库中。数据保留在远程服务器内部。
使用 Wrappers 进行 ETL
ETL 代表提取(Extract)、转换(Transform)、加载(Load)。它是一个将数据从一个系统移动到另一个系统的既定过程。例如,将数据从生产数据库移动到数据仓库是很常见的做法。
有许多流行的 ETL 工具,如 Fivetran 和 Airbyte。
Wrappers 提供了这些工具的替代方案。您可以使用 SQL 将数据从一个表移动到另一个表:
-- Copy data from your production database to your
-- data warehouse for the last 24 hours:
insert into warehouse.analytics
select * from public.analytics
where ts > (now() - interval '1 DAY');
这种方法提供了几个好处:
-
简单易用: Wrappers API 只是 SQL,因此数据工程师不需要学习新工具和语言。
-
节省时间: 避免设置额外的数据管道。
-
节省数据工程成本: 管理的基础设施更少。
一个缺点是 Wrappers 并不像 ETL 工具那样功能丰富。它们还将 ETL 过程与您的数据库耦合起来。
按需 ETL 与 Wrappers
Supabase 通过实时数据访问扩展了 ETL 概念。您不必在查询之前将大量数据从一个系统移动到另一个系统,而是可以直接从远程服务器查询数据。这种额外的选项,“查询”(Query),扩展了 ETL 过程,被称为 QETL:查询、提取、转换、加载。
-- Get all purchases for a user from your data warehouse:
select
auth.users.id as user_id,
warehouse.orders.id as order_id
from
warehouse.orders
join
auth.users on auth.users.id = warehouse.orders.user_id
where
auth.users.id = '<some_user_id>';
这种方法有几个好处:
-
按需: 分析数据立即在您的应用程序中可用,无需额外的基础设施。
-
始终同步: 由于数据是直接从远程服务器查询的,因此它始终是最新的。
-
集成: 大型数据集在您的应用程序中可用,并且可以与您的操作/事务数据结合。
-
节省带宽: 只提取/加载您需要的内容。
使用 Wrappers 进行批处理 ETL
Wrappers 的一个常见用例是从生产数据库提取数据并将其加载到数据仓库中。这可以在您的数据库中使用 pg_cron 来完成。例如,您可以安排一个每天晚上运行的任务,从您的生产数据库提取数据并将其加载到您的数据仓库中。
-- Every day at 3am, copy data from your
-- production database to your data warehouse:
select cron.schedule(
'nightly-etl',
'0 3 * * *',
$$
insert into warehouse.analytics
select * from public.analytics
where ts > (now() - interval '1 DAY');
$$
);
如果您正在移动大量数据,这个过程可能会对您的数据库造成负担。通常,使用像Fivetran 或 Airbyte 这样的外部工具进行批处理 ETL 更好。
安全
外部数据封装器不提供行级安全性。我们不建议通过您的 API 公开它们。封装器应该始终存储在私有模式中。例如,如果您正在连接到您的 Stripe 账户,您应该创建一个 stripe 模式来存储所有您的外部表。这个模式不应该被添加到 API 部分的“额外模式”设置中。
如果您想要将任何列公开到您的公共 API,可以在 public模式中创建一个 视图。您也可以在 数据库函数 中与您的外部表交互。