总览
随着ChatGPT的爆火,人们逐渐认识到大语言模型(LLM)和生成式人工智能在多个领域具有潜力,如文稿撰写、图像生成、代码优化和信息搜索等。LLM已成为个人和企业的有力助手,引领着新的生态系统。本文将介绍Embedding相关概念以及构建由LLM驱动的专属AI对话机器人总体流程。
背景
AI领域技术不断突破,越来越多的企业和个人积极探索利用大型语言模型(LLM)和生成式人工智能技术,来构建专注于特定领域的具备人工智能能力的产品。目前大型语言模型在解决通用问题方面表现出色,但由于受到训练数据和模型规模的限制,其在专业知识和时效性方面存在一定局限性。例如ChatGPT的训练的数据都是2021年及以前的,这也意味着想要咨询2021年以后的知识ChatGPT并不能给出准确的回答。
在信息时代,企业的知识库更新速度不断加快。因此,对于企业而言,如果希望在大型语言模型的基础上构建特定垂直领域的人工智能产品,就需要将自身的知识库输入到大型语言模型中进行训练。但是要知道,一个大语言模型的参数动辄上百数千亿。单单本地的一点知识库放进去就是沧海一粟。很难达到想要的效果。加之对硬条件要求过高,很少企业和个人有条件能够直接“投喂”到模型里面训练。
目前有两种常见的方法实现:
- 微调(Fine-tuning):通过提供新的数据集对已有模型的权重进行微调,不断更新输入以调整输出,以达到所需的结果。这适用于数据集规模不大或针对特定类型任务或风格进行训练。
- 提示调整(Prompt-tuning):通过调整输入提示而非修改模型权重,从而实现调整输出的目的。相较于微调,提示调整具有较低的计算成本,需要的资源和训练时间也较少,同时更加灵活。 但随着语言模型越来越大,Fine-tune的成本也越来越高。目前市面上已经涌现许多由大语言模型驱动的专属AI对话机器人,这些大都是通过提示调整来实现建立本地化AI知识库。
实现原理
本文将展示开发一款专属AI对话机器人的流程:
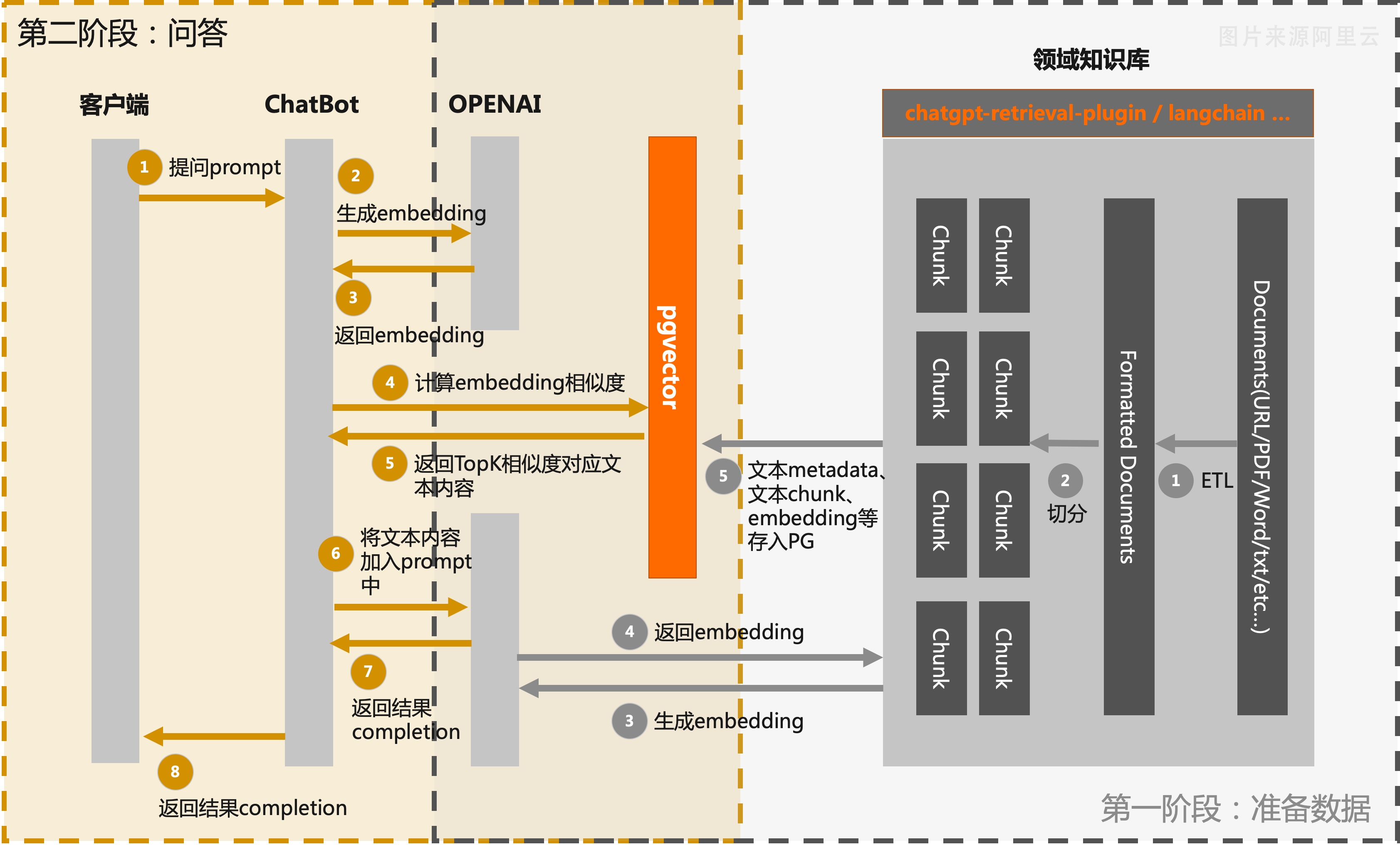
第一阶段:数据准备
- 知识库信息提取和分块:从领域知识库中提取相关的文本信息,并将其分块处理。这可以包括将长文本拆分为段落或句子,提取关键词或实体等。这样可以将知识库的内容更好地组织和管理。
- 调用大语言模型接口生成Embedding:利用大语言模型(如OpenAI)提供的接口,将分块的文本信息输入到模型中,并生成相应的文本Embedding。这些Embedding将捕捉文本的语义和语境信息,为后续的搜索和匹配提供基础。
- 存储Embedding信息:将生成的文本Embedding信息、文本分块以及文本关联的metadata信息存入MemFireCloud PostgreSQL数据库中。
第二阶段:问答
- 用户提问。
- 通过OpenAI提供的Embedding接口创建该问题的Embedding。通俗的说就是你发出的提问内容A,通过OpenAI的接口,返回问题内容A的一个向量,也就是我们之前说的Embedding。
- 因为在步骤1我们已经将我们的本地的知识库进行分片和Embedding,我们现在只需要将A的Embedding值和我们知识库分片的Embedding值进行比对,通过pgvector这个扩展,能够帮我们过滤出PostgreSQL数据库中相似度大于一定阈值的文档块.
- 然后将我们的提问内容A和过滤出来的文档块,作为prompt一同发送给OpenAI,并将OpenAI结果返回给用户。这样一来,用户得到的就是逻辑严谨准确率高且符合人类语法的回答。
流程图如下:
关于产品
MemFire Cloud提供了一个开源工具包,用于使用Postgres和pgvector开发人工智能应用程序。使用MemFire Cloud客户端库,在规模上存储、索引和查询你的Embedding。 这个工具包含以下功能:
- 使用 Postgres 与 pgvector 来实现 向量存储 和嵌入支持。
- 提供 Python客户端 ,用于管理非结构化嵌入。
- 提供 数据库迁移 ,用于管理结构化嵌入。
- 支持与多个流行的 AI 供应商 (如 OpenAI 、 Hugging Face 、LangChain 等) 进行集成。
相关概念 | Embedding
当谈到"Embedding"时,它通常是指将高维数据转换为低维表示的过程。在自然语言处理(NLP)和机器学习领域,“Embedding"通常用来将单词、短语、文本或者图像数据转换为向量(也称为嵌入向量或词嵌入)。因为计算机是擅长处理数字运算的,所以将无法计算的文本数据转化为向量数据,从而便于后面的计算。 你可能会疑问这些文本数据是如何转换成向量的,这又是如何规定的。接下来我将会为您讲解。
我们描述一个人可以有很多形容词,假定我们有4个人(张三、李四、王五、赵六),给每个人都从“可爱的”、“高挑的”、“高智商的”、“善解人意的”、“多愁善感的”这5个方面进行描述。符合定义为1,不符合定义为0,那么这4个人的描述可能是:
[1,0,1,0,0]
[1,1,0,0,1]
[0,0,1,1,1]
[1,1,1,0,0]
每个向量都有5个维度,每个维度都代表一个方面的描述。从左到右的依次表示为:“可爱的”、“高挑的”、“高智商的”、“善解人意的”、“多愁善感的”。向量1-4分别代表:张三、李四、王五、赵六。如此,我可以得知张三不仅长得可爱还高智商。这种张三对应向量[1,0,1,0,0]这种对应关系不是为了某种目的进行的,它只是一种泛泛的描述,还不能叫做Embedding。 我们接着往下看。也把上面的5个维度扩展一下,增加“名校学历”、“勤奋”、“守时”、“诚实”、“外向”5个维度,构成10个维度进行考察评估,在面试考察中可能得到的结果是一组10维向量:
[1,0,1,0,0,0,1,1,1,0]
[1,1,0,0,1,1,1,0,1,0]
[0,0,1,1,1,1,1,0,0,0]
[1,1,1,0,0,0,1,1,1,1]
这个时候我们可以得出,张三是一个长得可爱,智商高,勤奋,守时,诚实的人。 当我们考虑“招聘程序员”这个场景,那么这10个维度的描述似乎不大能看出这个人的是否符合我们的职位要求。也就是说,这10个维度取的不大合适。这时候我们可能需要替换一下考察维度。比如替换为“熟悉数据结构”、“具有大型线上项目经验”、“精通C++”、“带过团队”、“持续学习”、“名校学历”、“勤奋”、“守时”、“诚实”、“外向” 这时我们得到一组新的向量。
[1,1,1,1,1,0,1,1,1,0]
[0,0,1,0,1,1,1,0,1,0]
[1,0,0,0,1,1,1,0,0,0]
[0,1,1,0,0,0,1,1,1,1]
此时我们可以看出张三对应[1,1,1,1,1,0,1,1,1,0],得出张三是熟悉数据结构、具有大型线上项目经验、精通C++、带过团队、持续学习、非名校学历、勤奋、守时、诚实、不外向的人。 这么看,这个人似乎很符合岗位的需要,于是决定发offer。这种面向一定目的的描述,可以被称为Embedding
在这个例子中,“具有大型线上项目经验”、“精通C++”、“带过团队”、“持续学习”、“名校学历”、“勤奋”、“守时”、“诚实”、“外向” 这10个维度比“可爱,高挑,高智商,善解人意,多愁善感,名校,勤奋,守时,诚实,内向”这10个维度明显更符合我们的招聘目的。也就是说,Embedding的好坏至少有两个方面的因素:1.维度是否合适 2.维度上的描述值是否准确。
在以上的例子中我们只是用0代表不属于该属性,1代表属于该属性。然而这种表示方式非常稀疏且维度很高,导致数据稀疏性和计算资源消耗的问题。但是在现实案例中我们经常会遇到数值连续变化的情况。比如在0到1之间的0.5又表示什么呢?在实际处理过程中我们通常是用该维度下的数值反应与该维度的相关程度,数值越大,表明越相关。而Embedding的目标是将这些高维稀疏的表示转换为低维稠密的向量,以便更有效地表达文本信息和模式。
原理相同,我们把上面对人物的描述换成对词(可以是英文单词,也可以是中文的词)的描述,得到词向量。把离散的词数据转换成了计算机可以运算的连续数据。简而言之就是"Embedding"将文本中的单词或短语映射到连续向量空间中,这些向量在低维空间中表示了文本的语义信息和特征。通过Embedding,相似的单词或短语在向量空间中会更加接近,因为它们在语义上更相关。